Gated Recurrent Unit
Giới thiệu
GRU là một biến thể đơn giản và hiệu quả của mạng LSTM. GRU sử dụng ít gate và tham số hơn, giúp huấn luyện nhanh hơn và dễ dàng hơn nhưng vẫn quản lý tốt các phụ thuộc dài hạn (long-term dependencies) trong dữ liệu tuần tự.
Ta sẽ tìm hiểu kiến trúc của GRU, cách hoạt động và ứng dụng trong các bài toán như mô hình ngôn ngữ và dự đoán chuỗi thời gian.
GRU là gì?
GRU là một loại kiến trúc mạng RNN. GRU có cơ chế tương tự LSTM nhưng ít tham số hơn và không sử dụng trạng thái ô nhớ (Cell State). GRU được thiết kế để giải quyết vấn đề tiêu biến gradient (vanishing gradient) thường gặp ở RNN truyền thống.
Tương tự LSTM, GRU sử dụng các cơ chế cổng (gating mechanisms) để chọn lọc cập nhật và quên thông tin theo thời gian, giúp ghi nhớ thông tin quan trọng trong chuỗi dài và xử lý hiệu quả các phụ thuộc ngắn hạn. Nói đơn giản, GRU giống như một hệ thống bộ nhớ thông minh trong mạng, quyết định nên nhớ gì và quên gì khi xử lý dữ liệu tuần tự.
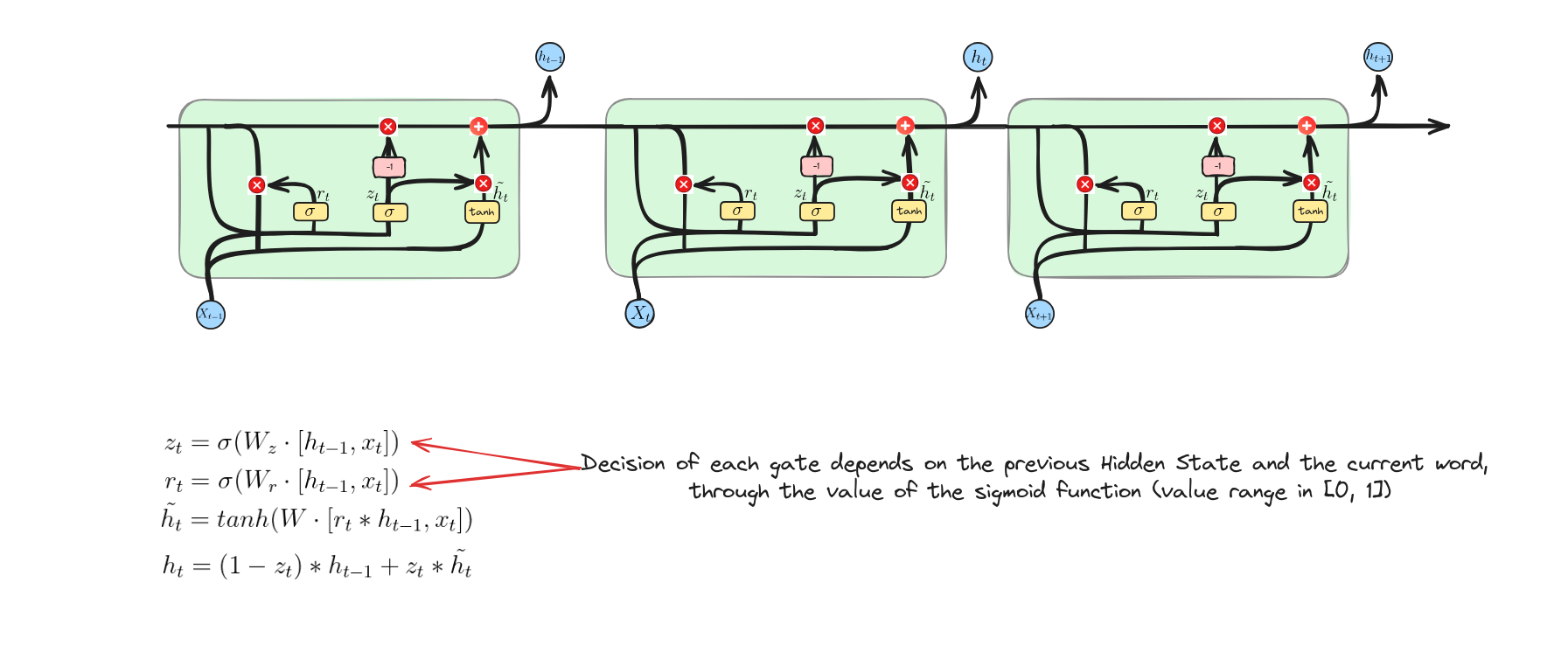
Kiến trúc của GRU
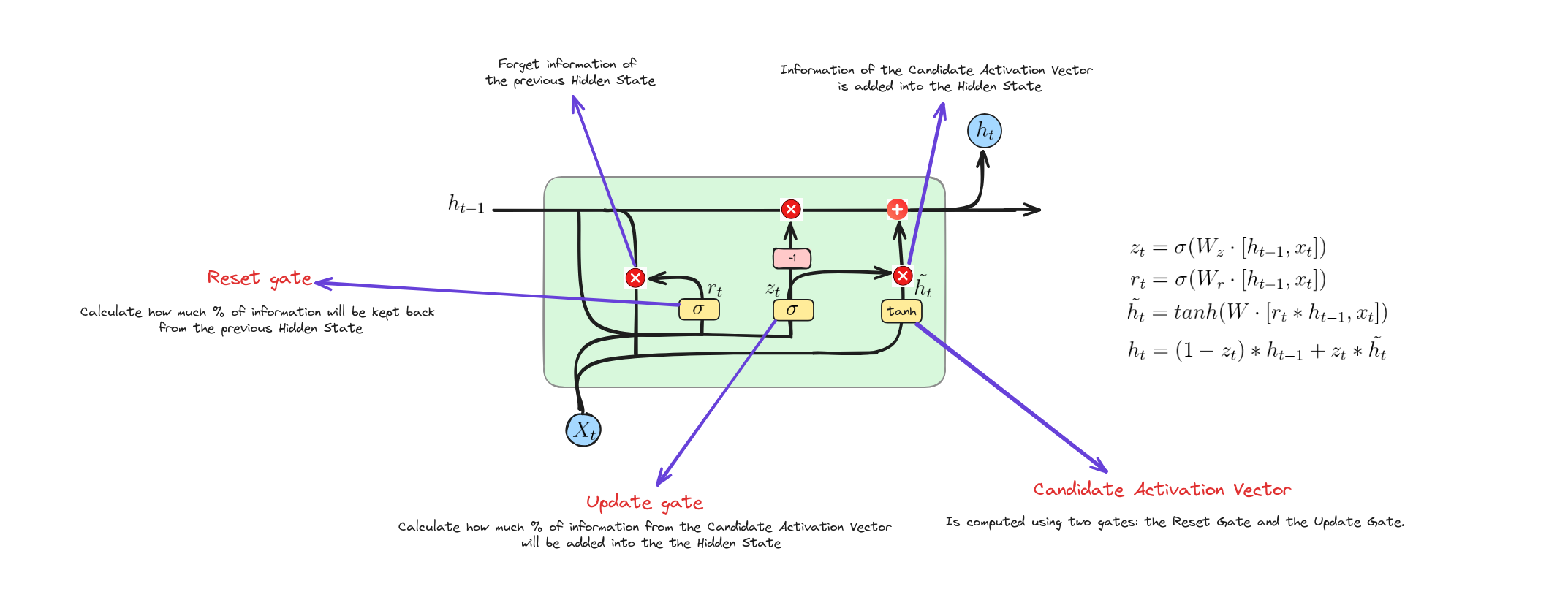
GRU hoạt động như thế nào?
Reset Gate
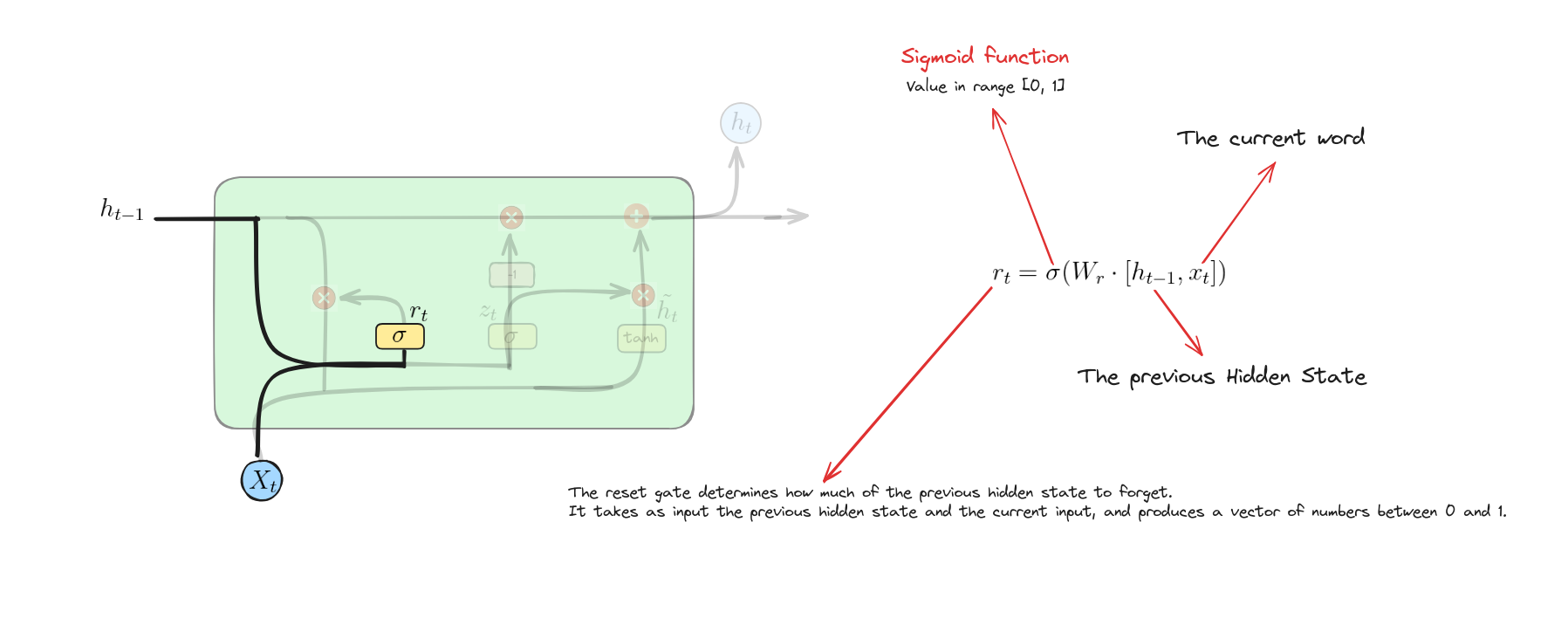
Phương trình này tính toán giá trị kích hoạt của cổng đặt lại bằng cách kết hợp trạng thái ẩn trước đó và đầu vào hiện tại, sau đó áp dụng hàm sigmoid để xác định mức độ thông tin quá khứ cần được đặt lại hoặc quên.
Update Gate
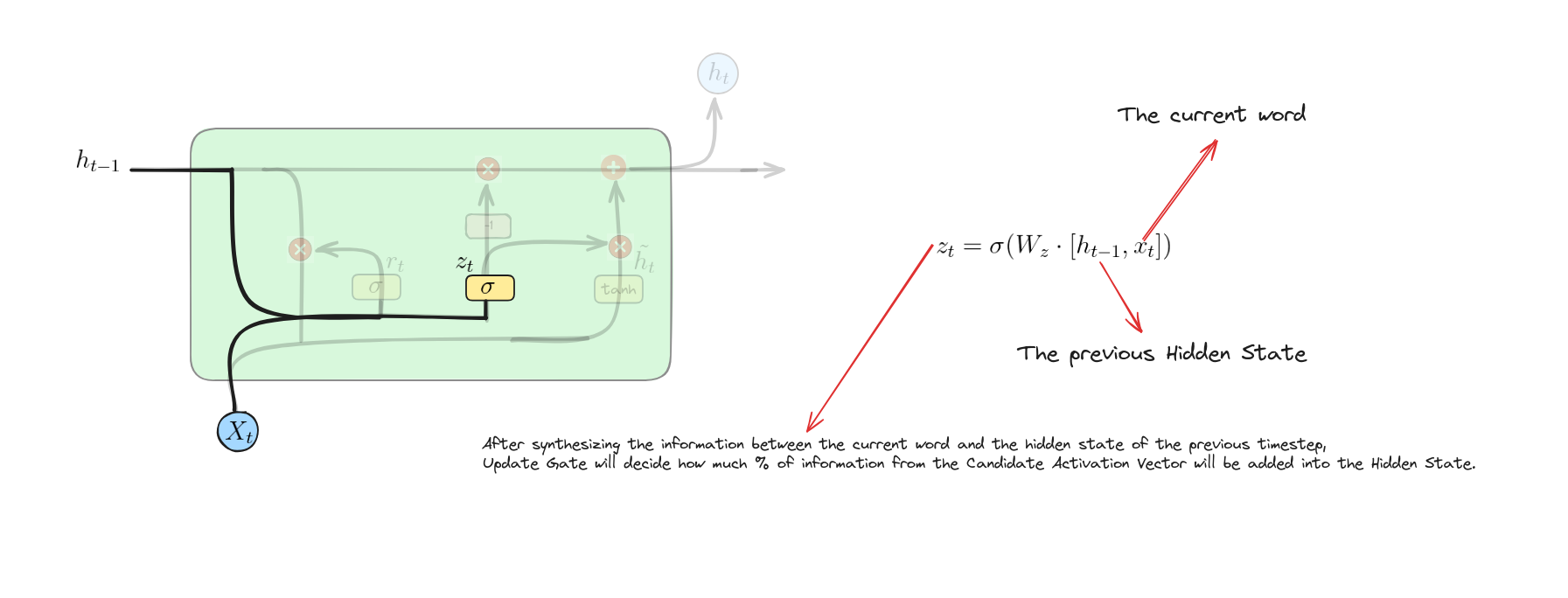
Phương trình này tính toán giá trị kích hoạt của cổng cập nhật bằng cách kết hợp trạng thái ẩn trước đó và đầu vào hiện tại, sau đó áp dụng hàm sigmoid để xác định giữ lại bao nhiêu trạng thái cũ và thêm bao nhiêu thông tin mới.
Candidate Activation Vector
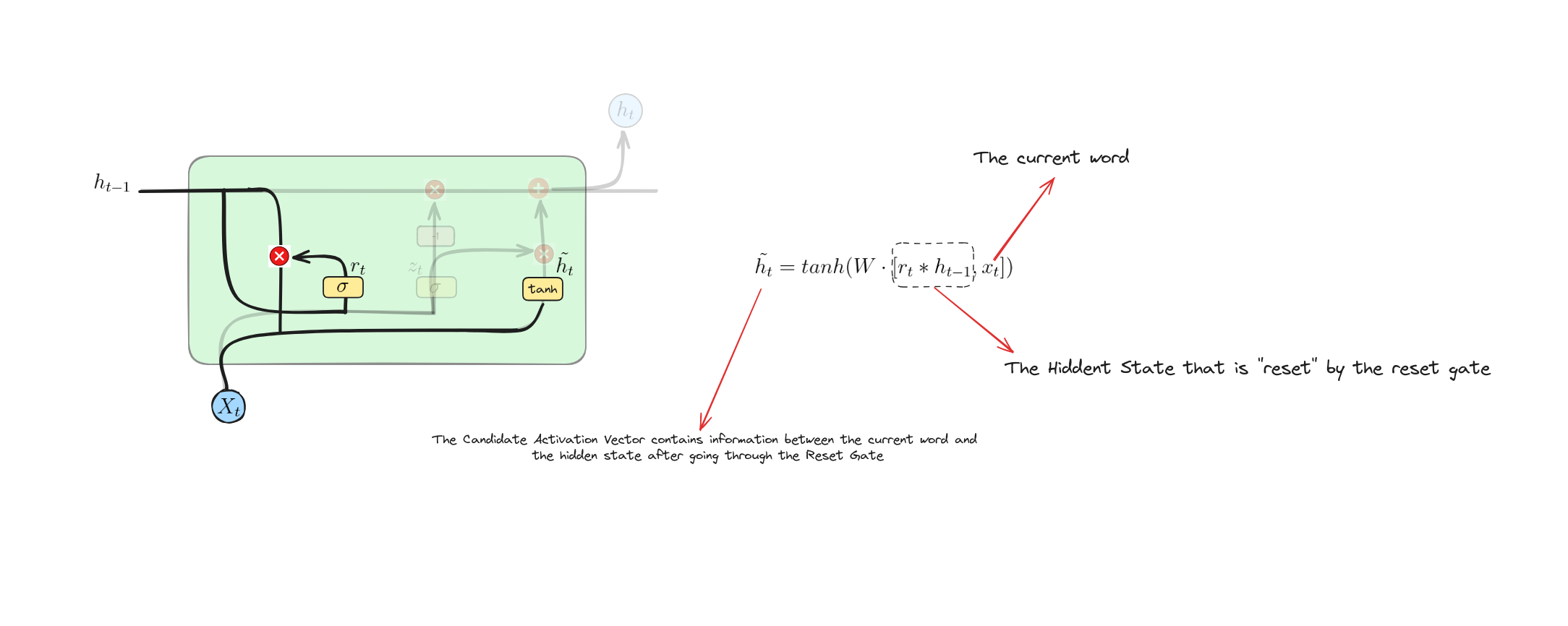
Phương trình này tính toán trạng thái ẩn ứng viên bằng cách nhân trạng thái ẩn trước $h_{t-1}$ với cổng đặt lại $r_{t}$ (cho phép mô hình quên một phần trạng thái cũ nếu cần). Sau đó, trạng thái đã được nhân và đầu vào $x_{t}$ được kết hợp, đưa qua ma trận trọng số $W$ và hàm kích hoạt $tanh$ để tạo ra trạng thái ẩn ứng viên $\tilde{h}_{t}$.
Update Operation
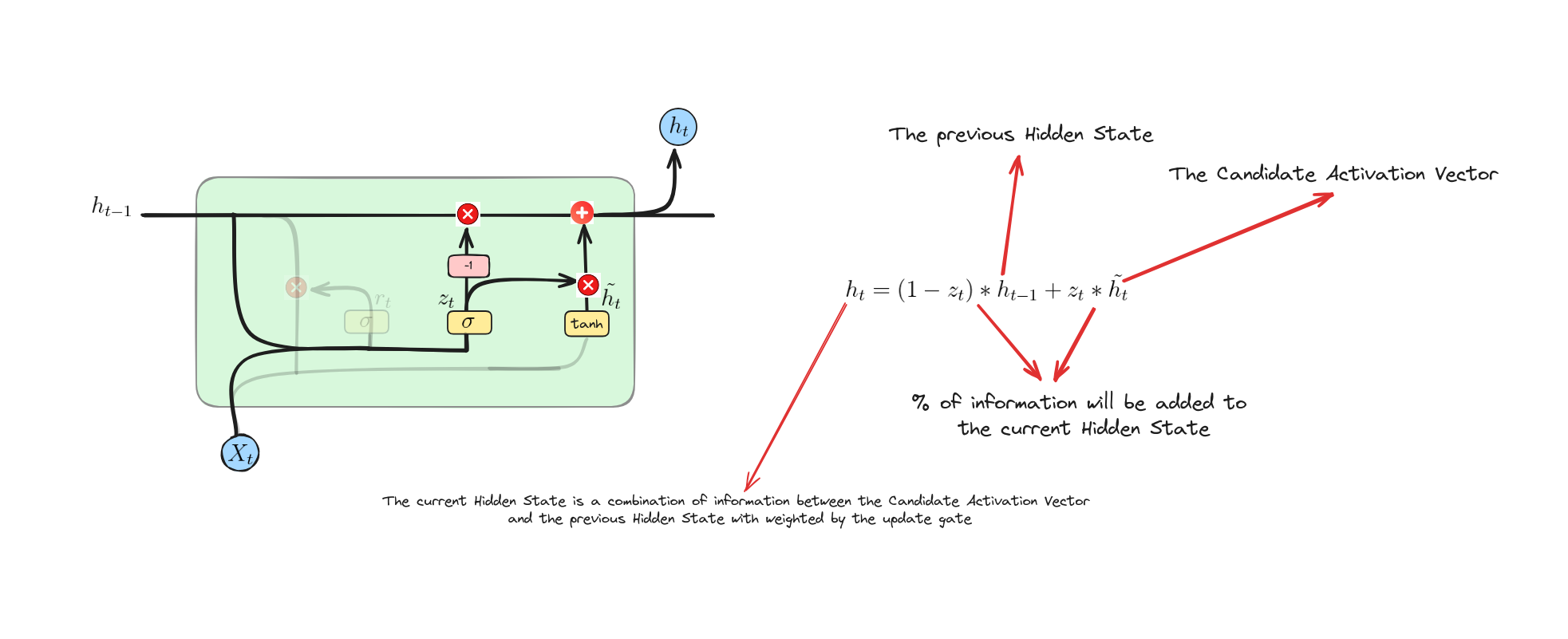
Phương trình này trộn trạng thái ẩn cũ $h_{t-1}$ với ứng viên mới $\tilde{h}{t}$ dựa trên cổng cập nhật $z{t}$. Nếu $z_{t}$ gần 1, trạng thái mới $h_{t}$ chủ yếu dùng ứng viên $\tilde{h}{t}$. Nếu $z{t}$ gần 0, giữ lại nhiều trạng thái cũ $h_{t-1}$ hơn.
Make a decision
Triển khai mô hình GRU (Implement GRU Model)
Trong phần này, chúng ta sẽ xây dựng một mô hình GRU để phát hiện châm biếm (Sarcasm Detection) và so sánh với mô hình LSTM ở bài trước. Bài lab này được thực hiện trên Google Colab.
Download dataset
Chúng ta sẽ sử dụng News Headlines Dataset cho dự án này. Bộ dữ liệu được thu thập từ hai trang tin TheOnion và HuffPost. Mỗi bản ghi gồm 3 thuộc tính:
- is_sarcastic: 1 nếu là châm biếm, 0 nếu không
- headline: tiêu đề bài báo
- article_link: liên kết đến bài báo gốc (hữu ích để thu thập thêm dữ liệu)
!wget https://raw.githubusercontent.com/dunghoang369/data/master/Sarcasm_Headlines_Dataset.json
Import các thư viện cần thiết (Import necessary libraries)
import json
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras.models import Sequential
from sklearn.metrics import classification_reportEach record consists of three attributes:
from tensorflow.keras.layers import Embedding, Dense, GRU, Bidirectional
Tải dữ liệu (Load dataset)
df = pd.read_json("Sarcasm_Headlines_Dataset.json", lines=True)
datastore = df.to_json()
datastore = json.loads(datastore)
Tách đặc trưng (Split features)
article_link_datastore = datastore["article_link"]
headline_datastore = datastore["headline"]
sarcastic_datastore = datastore["is_sarcastic"]
sentences = []
urls = []
labels = []
table = str.maketrans('', '', string.punctuation)
for key in article_link_datastore:
sentences.append(headline_datastore[key].lower())
urls.append(article_link_datastore[key])
labels.append(sarcastic_datastore[key])
# In ra một số mẫu dữ liệu
print("Sample 1: ", sentences[0], urls[0], labels[0])
print("Sample 2: ", sentences[1], urls[1], labels[1])
Sample 1: former versace store clerk sues over secret 'black code' for minority shoppers, https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5, 0
Sample 2: the 'roseanne' revival catches up to our thorny political mood, for better and worse, https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365, 0
Định nghĩa các siêu tham số (Define some hyperparameters)
vocab_size = 1000
embedding_dim = 16
max_length = 120
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"
training_size = 20000
Chia tập train, test (Split train, test datasets)
training_sentences = np.array(sentences[:training_size])
training_labels = np.array(labels[:training_size])
test_sentences = np.array(sentences[training_size:])
test_labels = np.array(labels[training_size:])
Xây dựng tokenizer (Build tokenizer)
tokenizer = tf.keras.preprocessing.text.Tokenizer(vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
training_sequences = tokenizer.texts_to_sequences(training_sentences)
test_sequences = tokenizer.texts_to_sequences(test_sentences)
Padding toàn bộ tập dữ liệu (Padding whole dataset)
training_padded = tf.keras.preprocessing.sequence.pad_sequences(training_sequences, maxlen=max_length, padding='post', truncating='post')
test_padded = tf.keras.preprocessing.sequence.pad_sequences(test_sequences, maxlen=max_length, padding='post', truncating='post')
Chúng ta sẽ thêm số 0 vào cuối mỗi chuỗi trong train_dataset và test_dataset để tạo các chuỗi có cùng độ dài trong một batch.
Xây dựng mô hình GRU hai chiều (Build Bidirectional GRU)
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=120))
model.add(Bidirectional(GRU(32)))
model.add(tf.keras.layers.Dense(24, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
print(model.summary())
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 120, 16) 16000
bidirectional (Bidirection (None, 64) 9600
al)
dense (Dense) (None, 24) 1560
dense_1 (Dense) (None, 1) 25
=================================================================
Total params: 27185 (106.19 KB)
Trainable params: 27185 (106.19 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
So với mô hình LSTM, GRU có ít tham số huấn luyện hơn nên sẽ huấn luyện nhanh hơn.
Huấn luyện mô hình (Train the model)
# Set up callbacks
checkpoint = tf.keras.callbacks.ModelCheckpoint('best.h5',
save_best_only=True,
mode='min')
callbacks = [checkpoint]
# Set up optimizer, loss function and metrics
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='binary_crossentropy',
metrics=['accuracy'])
# Train the model
model.fit(training_padded, training_labels, batch_size=32, epochs=50, callbacks=callbacks, validation_data=(test_padded, test_labels))
Đánh giá mô hình (Evaluate the model)
predictions = model.predict(test_padded)
predictions = np.array([1 if prediction[0] > 0.5 else 0 for prediction in predictions])
print(classification_report(test_labels, predictions))
210/210 [==============================] - 2s 7ms/step
precision recall f1-score support
0 0.83 0.80 0.81 3779
1 0.75 0.78 0.77 2930
accuracy 0.79 6709
macro avg 0.79 0.79 0.79 6709
weighted avg 0.79 0.79 0.79 6709
Suy luận (Inference)
def inference(text):
text = np.array([text])
sequences = tokenizer.texts_to_sequences(text)
padded = tf.keras.preprocessing.sequence.pad_sequences(sequences, maxlen=max_length, padding='post', truncating='post')
predict = model.predict(padded)
if predict > 0.5:
label = 1
else:
label = 0
print(f"Label: {['Sarcastic', 'Normal'][label]}")
1/1 [==============================] - 0s 20ms/step
Label: Sarcastic
Kết luận
Dựa trên đánh giá, có thể kết luận mô hình LSTM tốt hơn GRU một chút nhưng kích thước lớn hơn và thời gian huấn luyện lâu hơn. Đây là sự đánh đổi giữa hai mô hình.
Kết luận
Tóm lại, bài học về Gated Recurrent Unit (GRU) đã cho thấy cách mạng này xử lý các phụ thuộc dài hạn trong dữ liệu. Chúng ta đã tìm hiểu về cổng đặt lại (reset gate), cổng cập nhật (update gate) và cách chúng giúp kết hợp thông tin cũ mới để cập nhật trạng thái ẩn hiệu quả.
GRU đơn giản hơn, huấn luyện nhanh hơn LSTM, là lựa chọn tốt cho nhiều bài toán chuỗi.
Tài liệu tham khảo (References)
- M. Phi, “Illustrated Guide to LSTM’s and GRU’s: A step by step explanation,” Medium, Jul. 10, 2019. https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
- Anishnama, “Understanding Gated Recurrent Unit (GRU) in Deep Learning,” Medium, May 04, 2023. https://medium.com/@anishnama20/understanding-gated-recurrent-unit-gru-in-deep-learning-2e54923f3e2