Gán nhãn từ loại (POS - Parts-Of-Speech) trong NLP
Giới thiệu (Introduction)
Một nhiệm vụ thiết yếu trong Xử lý Ngôn ngữ Tự nhiên (NLP) là gán nhãn từ loại (Parts of Speech - PoS tagging), tức là gán các loại từ ngữ pháp như danh từ, động từ, tính từ, trạng từ cho từng từ trong văn bản. Điều này giúp máy tính hiểu và xử lý ngôn ngữ con người tốt hơn nhờ nắm được cấu trúc và ý nghĩa của cụm từ.
PoS tagging rất quan trọng cho các ứng dụng NLP như dịch máy (machine translation), phân tích cảm xúc (sentiment analysis), và truy xuất thông tin (information retrieval). Nó kết nối ngôn ngữ với khả năng hiểu của máy, cho phép phát triển các hệ thống xử lý ngôn ngữ nâng cao và phân tích ngôn ngữ sâu hơn.
Gán nhãn từ loại là gì? (What is POS Tagging?)
PoS tagging trong NLP là quá trình gán cho mỗi từ trong tài liệu một loại từ cụ thể, như trạng từ, tính từ, động từ… Việc này bổ sung thông tin cú pháp và ngữ nghĩa, giúp dễ dàng hiểu cấu trúc và ý nghĩa câu.
Trong NLP, PoS tagging hữu ích cho các nhiệm vụ như dịch máy, nhận diện thực thể (named entity recognition), và trích xuất thông tin. Nó giúp làm rõ các từ mơ hồ và thể hiện cấu trúc ngữ pháp của câu.

Ví dụ về gán nhãn từ loại (Example of POS Tagging)
Xét câu sau: “The big brown capybara is on the street.”

Việc gán nhãn này giúp máy không chỉ hiểu từng từ mà còn hiểu mối liên hệ giữa các từ trong cụm, cung cấp thông tin giá trị về cấu trúc ngữ pháp. Dữ liệu này rất quan trọng cho các nhiệm vụ NLP như tóm tắt văn bản, phân tích cảm xúc, và dịch máy.
Quy trình gán nhãn từ loại (POS Tagging Pipeline)
Một pipeline cho nhiệm vụ gán nhãn từ loại (POS tagging) thường gồm các bước chính sau:
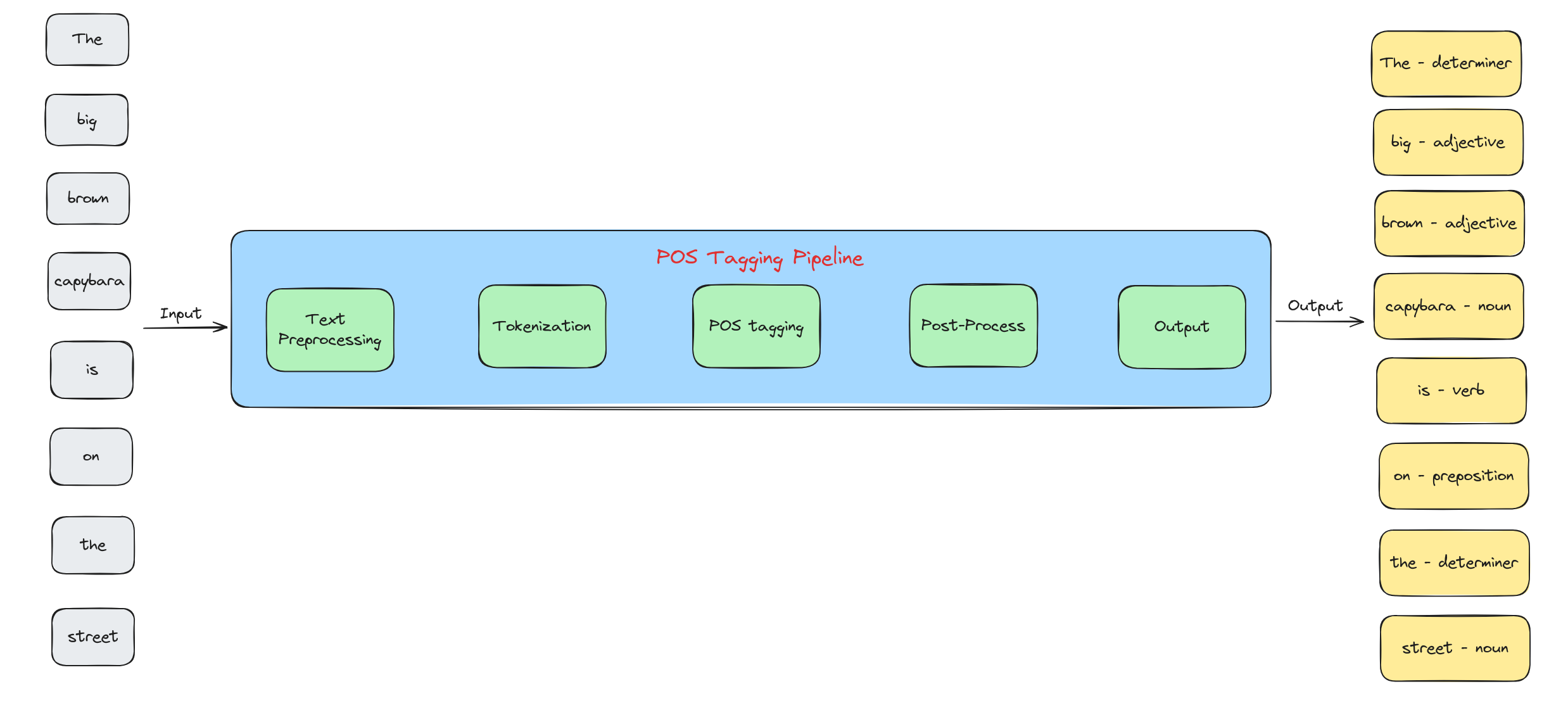
Tiền xử lý văn bản (Text Preprocessing): Làm sạch và tiền xử lý văn bản bằng cách loại bỏ dấu câu, chuyển về chữ thường, và tách từ (tokenization).
Tách từ (Tokenization): Chia văn bản thành các token (từ hoặc cụm từ) để phân tích.
Gán nhãn từ loại (POS Tagging): Sử dụng thuật toán hoặc thư viện gán nhãn từ loại (như NLTK, SpaCy, Stanford NLP) để gán nhãn cho từng token. Có thể dùng mô hình huấn luyện sẵn hoặc tự huấn luyện.
Hậu xử lý (Post-Processing): Tinh chỉnh và kiểm tra kết quả gán nhãn, sửa lỗi và đảm bảo nhất quán.
Đầu ra (Output): Sinh ra văn bản đã gán nhãn, dùng cho các tác vụ NLP tiếp theo hoặc phân tích.
Các loại gán nhãn từ loại trong NLP (Types of POS Tagging in NLP)
Gán nhãn từ loại (PoS tagging) là nhiệm vụ gán loại từ ngữ pháp cho các từ trong văn bản, rất quan trọng trong NLP. Có nhiều phương pháp gán nhãn từ loại khác nhau, mỗi phương pháp có cách tiếp cận riêng. Dưới đây là một số loại phổ biến.
Gán nhãn dựa trên luật (Rule-Based Tagging)
Phương pháp này sử dụng các luật ngôn ngữ học và từ điển được xác định trước để gán nhãn từ loại cho từ trong văn bản. Nó dựa vào các quy tắc thủ công và từ điển để xác định nhãn dựa trên hình thái và ngữ cảnh của từ.
Ví dụ, một bộ gán nhãn dựa trên luật có thể gán nhãn “danh từ” cho các từ kết thúc bằng “-tion” hoặc “-ment”. Phương pháp này minh bạch, dễ giải thích vì không phụ thuộc vào dữ liệu huấn luyện.
Gán nhãn dựa trên biến đổi (Transformation Based Tagging)
Phương pháp này còn gọi là Brill Tagging, áp dụng lặp lại các luật biến đổi được xác định trước để cải thiện nhãn từ loại ban đầu, dựa trên các mẫu ngữ cảnh.
Ví dụ, nhãn động từ có thể được đổi thành danh từ nếu nó đứng sau một từ xác định như “the”. Các luật này được áp dụng tuần tự, cập nhật nhãn sau mỗi lần biến đổi.
Phương pháp này có thể chính xác hơn gán nhãn dựa trên luật, nhất là với ngữ pháp phức tạp, nhưng cần nhiều luật và tài nguyên tính toán hơn để đạt hiệu quả tối ưu.
Gán nhãn từ loại dựa trên thống kê (Statistical POS Tagging)
Phương pháp này sử dụng mô hình xác suất và học máy để gán nhãn từ loại, thay vì dựa vào luật thủ công. Các thuật toán học xác suất của chuỗi từ-nhãn để nắm bắt mẫu ngôn ngữ. Các mô hình phổ biến gồm CRFs và Hidden Markov Models (HMMs).
Trong quá trình huấn luyện, thuật toán sử dụng dữ liệu đã gán nhãn để ước lượng xác suất một nhãn xuất hiện với từ và ngữ cảnh cụ thể. Khi áp dụng, mô hình dự đoán nhãn có xác suất cao nhất cho văn bản mới. Phương pháp này đặc biệt hiệu quả với ngôn ngữ có ngữ pháp phức tạp, vì xử lý tốt sự mơ hồ và các mẫu ngôn ngữ tinh vi.
Gán nhãn từ loại bằng mô hình Markov ẩn (Hidden Markov Model POS tagging)
Hidden Markov Models (HMMs) được sử dụng rộng rãi cho gán nhãn từ loại trong NLP. Chúng được huấn luyện trên tập văn bản lớn đã gán nhãn để nhận diện mẫu từ loại. Dựa vào huấn luyện này, HMM dự đoán nhãn từ loại cho một từ dựa trên xác suất các nhãn trong ngữ cảnh.
Một bộ gán nhãn HMM sử dụng các trạng thái cho các nhãn từ loại tiềm năng và chuyển đổi giữa chúng. Nó học xác suất chuyển đổi và xác suất sinh từ trong quá trình huấn luyện. Khi gán nhãn văn bản mới, nó dùng thuật toán Viterbi để tìm chuỗi nhãn từ loại có xác suất cao nhất.
HMM rất phổ biến trong NLP để xử lý dữ liệu chuỗi phức tạp, nhưng hiệu quả phụ thuộc vào chất lượng và số lượng dữ liệu huấn luyện.
Triển khai gán nhãn từ loại (Parts-of-Speech implementation)
Chúng ta sẽ sử dụng thư viện NLTK và SpaCy để thực hiện gán nhãn từ loại trong Python.
Triển khai gán nhãn từ loại bằng NLTK trong Python
Cài đặt thư viện
!pip install nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
Import thư viện
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag
Triển khai
# Sample text
text = "The big brown capybara is on the street."
words = word_tokenize(text)
# Performing PoS tagging
pos_tags = pos_tag(words)
# Displaying the PoS tagged result in separate lines
print("Original Text:")
print(text)
print("\nPoS Tagging Result:")
for word, pos_tag in pos_tags:
print(f"{word}: {pos_tag}")
which outputs:
Original Text:
The big brown capybara is on the street.
from nltk.tokenize import word_tokenize
from nltk import pos_tag
# Sample text
text = "The big brown capybara is on the street."
words = word_tokenize(text)
# Performing PoS tagging
pos_tags = pos_tag(words)
Original Text:
The big brown capybara is on the street.
PoS Tagging Result:
The: DT
big: JJ
brown: NN
capybara: NN
is: VBZ
on: IN
the: DT
street: NN
.: .
Đầu tiên, ta dùng hàm word_tokenize để tách văn bản thành các từ.
Sau đó, sử dụng hàm pos_tag từ NLTK để gán nhãn từ loại cho các từ đã tách.
Cuối cùng, in ra văn bản gốc và kết quả gán nhãn, mỗi từ cùng nhãn từ loại trên từng dòng riêng biệt.
Triển khai gán nhãn từ loại bằng SpaCy trong Python
Cài đặt thư viện
!pip install spacy
!python -m spacy download en_core_web_sm
Import thư viện
#importing libraries
import spacy
Triển khai
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Sample text
text = "The big brown capybara is on the street."
# Process the text with SpaCy
doc = nlp(text)
# Display the PoS tagged result
print("Original Text: ", text)
print("PoS Tagging Result:")
for token in doc:
print(f"{token.text}: {token.pos_}")
which outputs:
Original Text: The big brown capybara is on the street.
PoS Tagging Result:
The: DET
big: ADJ
brown: ADJ
capybara: NOUN
is: AUX
on: ADP
the: DET
street: NOUN
.: PUNCT
Ta sử dụng thư viện SpaCy và tải mô hình tiếng Anh “en_core_web_sm” bằng spacy.load(“en_core_web_sm”). Tiếp theo, văn bản mẫu được xử lý qua mô hình để tạo ra đối tượng Doc chứa các chú thích ngôn ngữ học. Sau đó, in ra văn bản gốc và lặp qua các token trong Doc, hiển thị từng token và nhãn từ loại tương ứng (token.pos_).
Lưu ý: Các mô hình POS tagging trong NLTK và SpaCy đều dựa trên phương pháp thống kê, đặc biệt là sử dụng mô hình Markov ẩn (HMM) đã huấn luyện.
Kết luận (Conclusion)
Trong bài học này, chúng ta đã tìm hiểu về gán nhãn từ loại (POS tagging)—một nhiệm vụ nền tảng trong NLP, giúp gán nhãn các từ trong câu với loại từ tương ứng như danh từ, động từ, tính từ… cũng như các phương pháp triển khai POS tagging.
Với kiến thức này, chúng ta có thể nâng cao phân tích văn bản bằng cách xác định chính xác cấu trúc ngữ pháp của câu.
Tài liệu tham khảo (References)
Geeksforgeeks, “NLP Part of Speech - Default Tagging,” GeeksforGeeks, Jan. 28, 2019. https://www.geeksforgeeks.org/nlp-part-of-speech-default-tagging/ - S. Mudadla, “What is Parts of Speech (POS) Tagging Natural Language Processing?In,” Medium, Nov. 09, 2023. https://medium.com/@sujathamudadla1213/what-is-parts-of-speech-pos-tagging-natural-language-processing-in-2b8f4b07b186